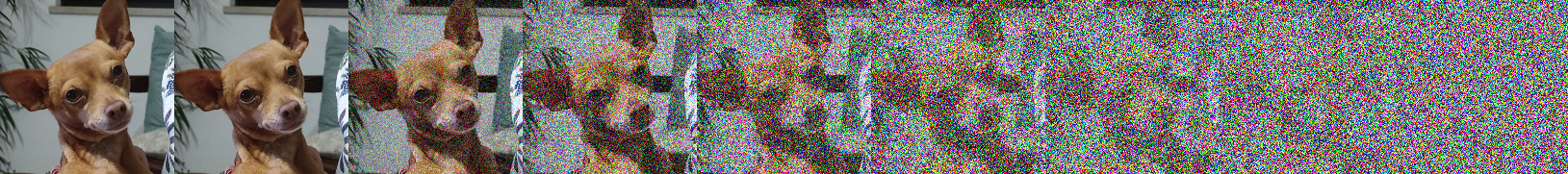In Diffusion Models, a noise type defines a specific parametrization of the stationary, prior, posterior, and approximate posterior distributions, q(xT), q(xt∣x0), q(xt−1∣xt,x0), and pθ(xt−1∣xt), respectively. Modular Diffusion includes the standard Gaussian noise parametrization, as well as a few more noise types.
Gaussian noise
Gaussian noise model introduced in Ho et al. (2020), for which the diffusion process is defined as:
parameter (default "x") -> Parameter to be learned and used to compute μ^θ. If "x" (x^θ) or "epsilon" (ϵ^θ) are chosen, μ^θ is computed using one of the formulas above. Selecting "mu" means that μ^θ is predicted directly. Typically, authors find that learning ϵ^θ leads to better results.
variance (default "fixed") -> If "fixed", the variance of pθ(xt−1∣xt) is fixed to 1−αˉt(1−αt)(1−αˉt−1)I. If "learned", the variance is learned as a parameter of the model.
Parametrization
If you have the option, always remember to select the same parameter both in your model’s Noise and Loss objects.
Example
from diffusion.noise import Gaussiannoise = Gaussian(parameter="epsilon", variance="fixed")
Visualization
Applying Gaussian noise to an image using the Cosine schedule with T=1000, s=8e−3 and e=2 in equally spaced snapshots:
Uniform categorical noise
Uniform categorical noise model introduced in Austin et al. (2021). In each time step, each token either stays the same or transitions to a different state. The noise type is defined by:
The Uniform noise type operates on one-hot vectors. To use it, you must use the OneHot data transform.
Parameters
k -> Number of categories k.
Example
from diffusion.noise import Uniformnoise = Uniform(k=26)
Visualization
Applying Uniform noise to an image with k=255 using the Cosine schedule with T=1000, s=8e−3 and e=2 in equally spaced snapshots:
Absorbing categorical noise
Absorbing categorical noise model introduced in Austin et al. (2021). In each time step, each token either stays the same or transitions to an absorbing state. The noise type is defined by: